Lak LakshmananinAI AdvancesGenerative AI Design PatternsA catalog of design patterns when building GenAI applicationsApr 31Apr 31
Lak LakshmananinBootcampCorporate blogs in the age of AIWhere marketing blogs and SEO are headed due to infusion of AI in both the production and consumptionMar 23Mar 23
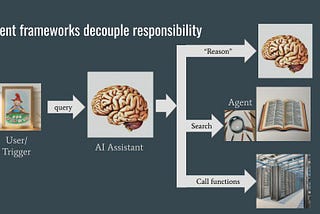
Lak LakshmananinTowards Data ScienceBuilding an AI Assistant with DSPyA way to program and tune prompt-agnostic LLM agent pipelinesMar 76Mar 76
Lak LakshmananinTowards Data ScienceAdvice on using LLMs wiselyTen of my LinkedIn posts on LLMsJan 42Jan 42
Lak LakshmananTen tips and tricks to employ in your Gen AI projectsLessons from a Production-ready Generative AI ApplicationOct 11, 20232Oct 11, 20232
Lak LakshmananGenerative AI: easy adoption, continuously improving, protecting content, hyperscale efficiencyFour extracts from my LinkedInAug 31, 2023Aug 31, 2023
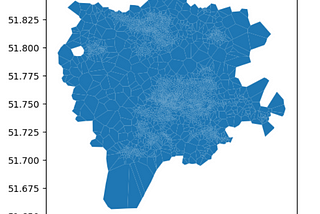
Lak LakshmananinTowards Data ScienceWorking with Geospatial Data at the Postcode LevelHow to associate “point” postcodes with area census dataJul 6, 2023Jul 6, 2023
Lak LakshmananinDataDrivenInvestorGetting value out of Voice AI one stage at a timeImproving the customer experience through automationMay 17, 2023May 17, 2023
Lak LakshmananinTowards Data ScienceFour Approaches to build on top of Generative AI Foundational ModelsWhat works, the pros and cons, and example code for each approachMar 21, 20239Mar 21, 20239
Lak LakshmananinTowards Data ScienceHow to Treat Data as a ProductMaximize the leverage you get from data by applying product management principlesFeb 8, 2023Feb 8, 2023